오늘은 로컬 환경에 Spark를 설치하는 방법에 대해서 정리해보려고 한다. 하지만 처음 설치하려고 하면, 특히 Windows 환경에서는 몇 가지 설정 과정이 다소 복잡하다(자꾸 안돌아가서 깨끗하게 전부 삭제하고 처음부터 다시 하는 중인 나같은 사람이 더이상 없기를). 이 글에서는 Windows 환경에서 Spark를 설치하는 단계를 아주아주 자세히 알아보려고 한다.
Spark 홈페이지
릴리스 노트나 예시 쉘 같은걸 확인할 수 있다. 당연히 한국어는 없지만 구글번역기로 돌려서 보면 된다.
https://spark.apache.org/docs/latest/
Overview - Spark 3.5.3 Documentation
Downloading Get Spark from the downloads page of the project website. This documentation is for Spark version 3.5.3. Spark uses Hadoop’s client libraries for HDFS and YARN. Downloads are pre-packaged for a handful of popular Hadoop versions. Users can al
spark.apache.org
[1] JDK 설치 및 자바 환경변수 설정
1. 여기에 들어가서 로그인(혹은 회원가입)한다.
2. Java 11 윈도우 installer를 다운로드 받는다. 사이트 들어가면 최신버전 자바 다운로드가 보이는데 스크롤을 내리면 11을 다운받을 수 있다. 다운로드 받은 후에 exe파일을 실행해서 설치한다.

3. 🔎 시스템 환경 변수 편집 - 환경 변수 클릭 - 시스템변수 새로 만들기 클릭 - 변수 이름과 변수 값 설정 후 확인
- 변수 이름: JAVA_HOME
- 변수 값: 다운로드한 자바 경로를 복사붙여넣기 or 디렉터리 찾아보기 클릭 후 자바가 있는 폴더 찾기
4. 시스템 변수의 변수 목록에서 Path 찾기 - 편집 - 새로 만들기 - %JAVA_HOME\bin 추가
5. cmd 창에 들어가서 java -version을 입력해본다. 이렇게 버전명이 잘 뜨면 설치가 완료된 것임.
[2] Python 또는 Scala 설치
나는 Python이 이미 있어서 요 단계는 패스
[3] Spark 설치 및 환경변수 설정
1. 스파크 홈페이지에서 스파크를 다운로드한다. 첫 페이지에 나오는게 최신 릴리스일텐데, 나는 그냥 최신으로 받았다.
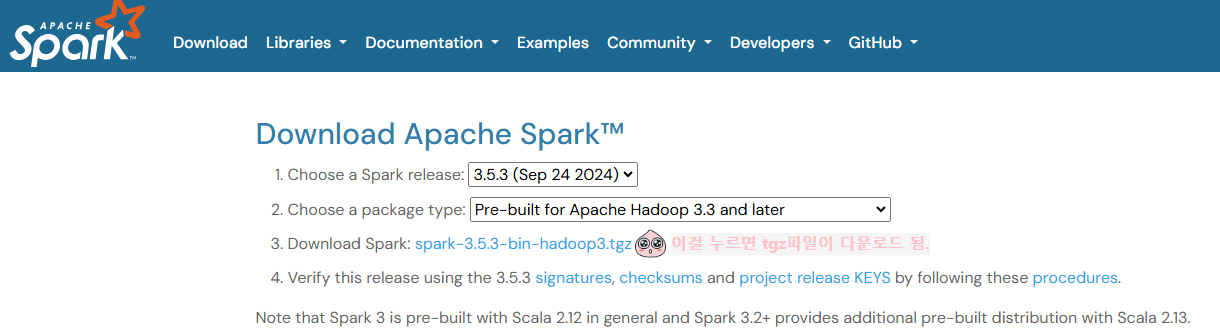
2. C드라이브 아래에 spark라는 폴더를 하나 생성한다. 그냥 새로만들기 - 폴더 - 이름 spark 하면 된다. 다운로드 받은 tgz파일을 방금 만든 폴더에 넣는다.


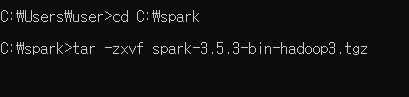
3. cmd 창을 열어 spark폴더로 이동 - 파일 압축해제를 한다. cd C:\spark 엔터 치고 디렉터리가 이동된 것을 확인 후 >tar -zxvf 압축해제파일명 을 적어준다. 파일 폴더가 생기면 압축 해제 끝.
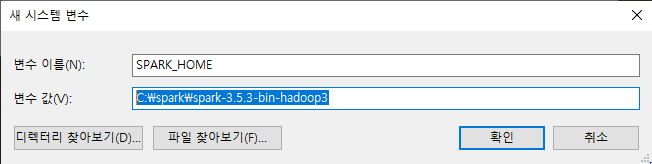
4. 또 돌아온 환경변수 설정 타임 // 환경변수 - 시스템 변수 - 새로 만들기 - SPARK_HOME 환경변수 추가
- 변수 이름: SPARK_HOME
- 변수 값:C:\spark\spark-3.5.3-bin-hadoop3 (버전 다르다면 설치한 파일대로 적어주기)
5. 시스템 변수의 변수 목록에서 Path 찾기 - 편집 - 새로 만들기 - %SPARK_HOME\bin 추가
(아까 위에서 JAVA_HOME 추가한 거랑 똑같은 방법)
[5] Hadoop 설치 및 환경변수 설정
1. C드라이브에 Hadoop 폴더 생성 - Hadoop 폴더에 bin 폴더 생성


2. 깃허브에서 winutils.exe를 다운로드 받는다. 기본적으로 이것만 있어도 동작하지만, 복잡한 것을 시도하려면 다른 파일도 필요하다고 한다. 나는 나중에 필요할 때 받으려고 그냥 exe만 다운로드 받았다.
3. 다운받은 exe파일을 1번에서 만든 Hadoop - bin 폴더에 옮긴다.

4. 또또 돌아온 환경변수 설정 타임 // 환경변수 - 시스템 변수 - 새로 만들기 - HADOOP_HOME 환경변수 추가
- 변수 이름: HADOOP_HOME
- 변수 값:C:\Hadoop

5. 시스템 변수의 변수 목록에서 Path 찾기 - 편집 - 새로 만들기 - %HADOOP_HOME\bin 추가

[드디어 끝] 잘 설치 되었는지 확인해보기
cmd 창 열고 spark-shell 입력
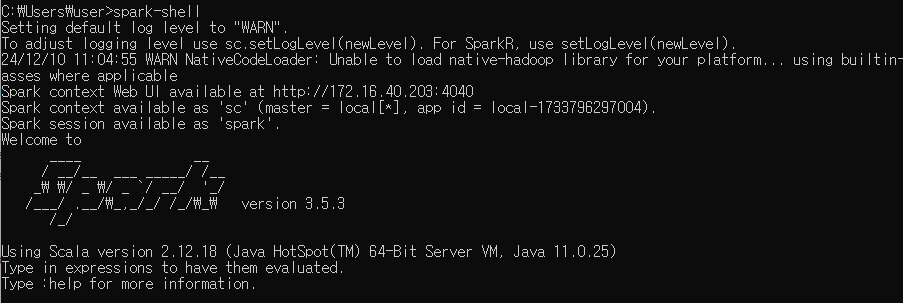
이렇게 로고와 버전이 보이면 끝!
다음 포스팅부터는 pyspark로 뭔가 해보고,,, spark가 뭔지 더 구체적으로 공부 후에 적어볼 생각이다. 12월 말까지는 어느정도 능숙하게 사용하는 걸 목표로 해보려고 한다
참고 블로그
https://it-is-my-life.tistory.com/23
[Apache Spark] 로컬 환경에서 Apache Spark 설치하기
로컬 환경에서 단일 클러스터로 Apache Spark를 설치하기 위해서는 1. JDK 설치 2. Python 설치 3. Apache Spark 설치 4. Hadoop Winutil 설치 5. 시스템 환경변수 설정 이렇게 총 5단계를 거쳐야 한다. 1. JDK 설치 Ap
it-is-my-life.tistory.com
Apache Spark 로컬 환경 구성
사전 요구 사항: Python 1. 자바 설치 1) 자바 다운로드 및 경로 지정 https://www.oracle.com/in/java/technologies/downloads/ D:\jdk-21.0.2 2) 시스템 변수 편집 (JAVA_HOME) 시스템 환경 변수 편집 -> 시스템 변수 새로 만
jysim.xyz
https://boring-notes.tistory.com/entry/Spark-Windows-%EC%84%A4%EC%B9%98
[Spark] Spark Windows 설치
Spark를 이용해 여러가지 테스트를 하기 위해 설치를 진행해 보았다 Linux 환경에 설치를 하거나 docker를 사용하는게 더 편하지만 환경이 여의치 않아 Windows OS의 PC에 설치해 보았다 Spark를 설치하고
boring-notes.tistory.com
'데이터사이언티스트로 살아남기 > 빅데이터' 카테고리의 다른 글
| [스파크 완벽 가이드] 2장. 스파크 간단히 살펴보기(2) (3) | 2024.12.17 |
|---|---|
| [스파크 완벽 가이드] 2장. 스파크 간단히 살펴보기(1) (2) | 2024.12.16 |