※ 혼자 책보고 공부하면서 적는거라 틀린 부분 있으면 댓글로 알려주세요!
YES24구매링크 - 별 의도는 없고 그냥 제가 예사에서 구매했어요...
스파크 완벽 가이드 - 예스24
스파크 창시자가 알려주는 스파크 활용과 배포, 유지 보수의 모든 것 오픈소스 클러스터 컴퓨팅 프레임워크인 스파크의 창시자가 쓴 스파크에 대한 종합 안내서이다. 스파크 사용법부터 배포,
www.yes24.com
CHAP2. 스파크 간단히 살펴보기(2) - 종합예제
1. 스파크로 데이터 읽어오기
- spark.read: Spark의 DataFrameReader를 사용해 데이터를 읽을 준비
- .option("inferSchema", "true"): CSV 파일의 각 열에 대한 데이터 타입을 자동으로 추론하여 읽어옴
- .option("header", "true"): 첫 번째 줄을 컬럼 이름으로 인식
flight_data_2015 = spark.read.option("inferSchema", "true").
option("header", "true").
csv("#파일경로")
여기까지만 하면 당연히 아무일도 안일어나기 때문에 액션을 호출해야 한다.
2. take 액션 호출하기
flight_data_2015.take(3)
3. explain 메서드를 호출하여 스파크의 실행계획 읽어보기
flight_data_2015.sort("count").explain()
#count 열을 기준으로 오름차순으로 정렬한 후, 그 실행 계획을 출력
구체적인 실행계획을 챗GPT와 함께 뜯어봤다.
위에서 아래 방향으로 읽으며, 최종 결과는 가장 위, 데이터 소스는 가장 아래에 있다.
- isFinalPlan=false: 현재 실행 계획이 최종이 아니라는 의미임. Spark가 실행 중에 이 계획을 조정할 수 있음
- +-Sort[count#39 ASC NULLS FIRST], true, 0
- sort: 데이터를 정렬하는 연산
- count#39 : count라는 열의 39번째 컬럼으로, 컬럼 ID임
- ASC NULLS FIRST: 정렬 기준은 오름차순(ASC), Null값을 먼저 오도록 조정
- 0: 정렬 버퍼 크기, 기본 정렬 방식 적용
- Exchange rangepartitioning(count#39 ASC NULLS FIRST, 200), ENSURE_REQUIREMENTS,[plan_id=99]
- Exchage: 데이터 교환
- rangepartitioning(): count열을 기준으로 범위 파티셔닝을 하여 200개 파티션으로 나눔. 이때 count컬럼을 기준으로 정렬된 상태로 데이터가 나누어짐
- ENSURE_REQUIREMENTS: 필요한 파티션 수를 보장하기 위함
- plan_id = 99 실행 계획의 고유 ID
- +- FileScan csv [DEST_COUNTRY_NAME#37, ORIGIN_COUNTRY_NAME#38, count#39] Batched: false, DataFilters: [], Format: CSV, Location: InMemoryFileIndex(1 paths)[file:/D:/Spark_practice/2015-summary.csv], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:int>
- filescan csv: csv 파일을 읽어옴. []안의 열을 읽음
- Batched: false는 배치 방식으로 읽지 않고, 각 레코드를 즉시 처리
- Location~ : CSV파일의 경로를 나타냄, 파일이 메모리에 로드 된 상태임
- ReadSchema: 데이터를 읽을 때 사용할 스키마을 정의함. 여기서는 3개 컬럼이 정의되어 있는 걸 <>안에서 확인 가능
4. 트랜스포메이션 추가해보기
스파크는 셔플 실행 시 기본적으로 200개의 셔플 파티션이 생성됨. 값을 조정하여 파티션 수를 줄일 수 있음.
- spark.conf.set(): Spark의 설정 값을 변경해서 실행환경을 세팅할 수 있다.
- "spark.sql.shuffle.partitions": 셔플 시 파티션의 개수를 설정한다. 본 예제에선 5개의 파티션으로 나누어 처리
spark.conf.set("spark.sql.shuffle.partitions","5")
flight_data_2015.sort("count").take(2)파티션 값을 200으로도 변경해봤다. 런타임이 달라진다곤 하는데 데이터가 작아서 그런지 딱히 차이는 못느꼈다.

DataFrame과 SQL을 사용하는 복잡한 작업
스파크는 언어에 상관없이 같은 방식으로 트랜스포메이션을 실행한다.
스파크 SQL을 사용하면 모든 Dataframe을 테이블이나 뷰로 등록 후 SQL쿼리를 사용할 수 있다.
flight_data_2015.createOrReplaceTempView("flightData2015")
#createorreplacetempview를 호출하면 테이블/뷰로 만들 수 있음SQL과 Dataframe의 처리 방식이 어떻게 다른지 확인해봤다.
1. 각 목적지 국가별로 개수 세기
sql_way와 df_way가 실행계획이 완전히 똑같다. 개인적으로는 SQL쓴지 너무 오래되어서,, 데이터프레임 방식이 조금 더 편했던 것 같다.

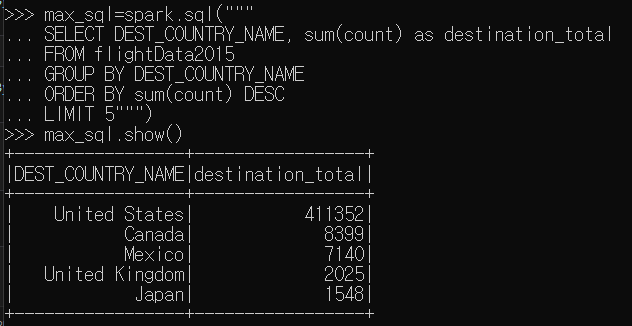
2. 상위 5개의 도착 국가 찾아내기(max함수)
max함수는 특정 컬럼값을 스캔하면서 이전 최댓값보다 더 큰 값을 찾아내는 트랜스포메이션이다.
요건 SQL방식. SQL이 익숙하면 이 방식이 편한 것 같다. 문제는 SQL한지가... 반년 넘어서 다 희미하게 남아있다는 것.
그래서 데이터프레임 구문으로 똑같은 걸 해봤다.
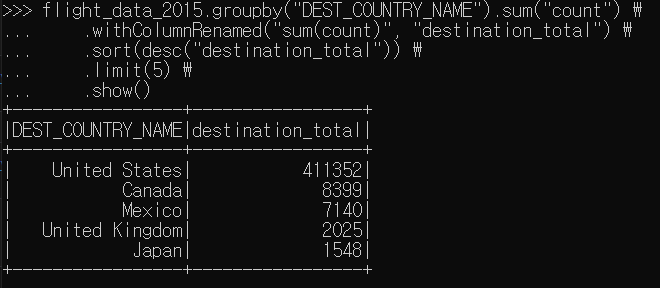
이렇게 써놓고 보니까 SQL이 더 나은 것 같기도 하고.. 편한 걸로 선택하면 되지 않을까 싶다.
+ 캡쳐를 못했는데 explain()으로 확인한 실행계획과 내가 쓴 코드 간의 차이가 좀 나는 것 같다.
아무튼 이렇게 아파치 스파크 기초 정리가 끝났다. 매번 말로만 스파크 스파크 했지 실제로 요렇게 해 보는 건 처음인데, 생각보다 괜찮았던 것 같다. 그리고 cmd로 하니까 눈아프다,, 조만간 vscode에 spark설치해서 거기서 연습해봐야겠다..
'데이터사이언티스트로 살아남기 > 빅데이터' 카테고리의 다른 글
| [스파크 완벽 가이드] 2장. 스파크 간단히 살펴보기(1) (2) | 2024.12.16 |
|---|---|
| [Spark] Window10 로컬 환경에 Spark 설치하기 (2) | 2024.12.10 |